How Semantic Triples Assist Knowledge Graph Embeddings
Semantic triples and knowledge graph embeddings help content creators establish the topic hubs for which the business entity wants to be recognized.
Semantic triples are helpful to organizing and categorizing website content so that search engines can understand, rank, and populate knowledge panels easily. A set of three entities that codify a statement about semantic data requires a clear SEO content strategy. By implementing structured data and helpful context, semantic triples can help search engines better match a webpage’s content with related search queries. This results in more relevant and useful search results for users.
Table of Contents
- How Semantic Triples Assist Knowledge Graph Embeddings
- What are Semantic Triples?
- Benefits of A Foundational Semantic Triple Model
- Knowledge Graph Semantic Embedding
- Semantic Triples are Machine-Readable Representations of Knowledge
- SUMMARY: Semantic Triples Boost Context and Meaning of Content
My head has been in this for years. At first is is complex (and continous to be). So, first, I’ll provide some common question answers and definitions that I’ve grabbled with while seeking to provide better content and knowledge graph embeddings using semantic triples.
What are Semantic Triples?
Triples (known as semantic facts) are a method of expressing graph data. They convert unstructured text data into meaningful structured data for easier search consumption and are also known as “statements” or “RDF statements”. A triple id is made up of three components: A subject, a predicate, and an object. They are the most foundational aspect of how information is encoded in a knowledge graph using semantic web technologies.
A semantic triple typically consists of a head entity, relation, and tail entity to indicate that two entities share a relationship by a stated connection, such as Mouthguards, treat, TMJ. The sentence might read, “Mouthguards are used to treat sports-triggered TMJ” In 2023, the Knowledge Graph embedding algorithms have gained widely accepted recognition as an integral part of semantic question answering systems (QAS).
These embedding algorithms learn the representations (i.e., embeddings) of entities and relations in low-dimensional vector spaces. Such embeddings help search engines with extremely quick question answering within knowledge graphs. Even for large graph information retrieval, triples’ are processes in ways that go against traditional constructs.
According to Oxford Semantic Technologies, “Triples are a part of the RDF data model, and they have one additional and very important constraint—every item in an RDF triple must be uniquely identifiable via IRI, with the exception of blank nodes. According to the RDF standards, IRIs must take the form of a web address, but stripped back to its most basic utility, a IRI acts as a label for each item.” (RDF stands for Resource Description Framework)
The components of a triple, such as the statement “Northern Red Oaks have bright orange fall color”, consist of a subject (“Northern Red Oaks”), a predicate (“have”), and an object (“orange fall color”).
What is a Knowledge Graph Model?
Knowledge graphs (KGs) catorgize data from multiple sources, collect information about entities of a specified interest in a specific domain or task (i.e. people, places, things, or events), and establish node connections between them. A knowledge graph model helps mazimize your content marketing efforts by enhancing structured data. This can reduce vague assumptions about your content by infusing brand values into the model.
Semantic triples are a way of expressing graph data in knowledge graphs using semantic web technologies and entity extraction. I like how Ontotext explains this:
“The heart of the knowledge graph is a knowledge model: a collection of interlinked descriptions of concepts, entities, relationships and events. Knowledge graphs put data in context via linking and semantic metadata and this way provide a framework for data integration, unification, analytics and sharing.” – What is a Knowledge Graph?
A method of multi-strategy ontology mapping aids semantic expression when developing the process of knowledge graph modeling techniques.
What is entity extraction?
Entity extraction in the automic means to identify named entities from diverse model data. It is basic function of knowledge extraction efficiency for managing knowledge graph embeddings. Relation extraction seeks to remove complexities of how to pull out relations between entites.
Entity extraction, also known as named entity extraction, also know as named-entity recognition (NER), aid machine learning in effots to automatically identify or extract entities, like product, person names, organizations, locations, medical codes, time expressions, quantities, monetary values, variants, percentages, etc. It is a secondary task in information extraction that attempts to locate, understand, and classify named entities mentioned in unstructured text into pre-defined categories. [1]
Three basic language syntaxes exist for expressing semantic triples in schemas.
- JSON-LD
- Microdata
- RDF
With so much data online, these query languages help express the meaning of key concepts in your content. In some applications, RDF is classified as triple data, without schema or ontology information unless explicitly included in the RDF source. Which ever syntax you prefer using most, you are attaching semantic information to your content pieces and are strategically embedding machine-processable information.
Only recently has Google permitted mixing structured data formats.
What are the basic elements of a semantic triple?
To create a structured semantic triple, understand its three core elements:
- ID: Each ID is an entity.
- Property: Each entity has properties.
- Value: The value of an entity can be an ID of another entity.
The three different parts of your matching schema code can be described as: Type, Property and ID.
What are RDF N-Triples?
N-Triples is a line-based, plain text format for encoding an RDF graph.
RDF N-Triples are introduced on W3, November 4, 2023 as quoted triples that offer a fourth RDF term type. It states that they “which can be used as the subject or object of another triple, making it possible to make statements about other statements. RDF 1.2 N-Triples also adds support for directional language-tagged strings.” [2]
I’ve used JSON-LD markup the most as Google has stated it prefers this markup language. It is possible to leverage mulitple production environments, such as adding Microdata and RDFa. However, currently, problems can emerge; and we find them hard to detect. It takes skill to mix syntaxes.
Benefits of A Foundational Semantic Triple Model
Search engines are needed to make your content findable by your active audience. A primary value of the semantic triple data model is that it helps them identify the intent behind search queries. Structured data formation aids in information retrieval and validation by making each triple like a classical relational database entity–attribute–value model.
By writing Triples or subject → verb → object formats, your content translates easily to structured data. Search engines seek and consume triples more easily. This saves resouces; it assists the calculation of semantic similarities.
Semantic triples can improve SEO efforts by:
- Making content’s language easy to understand.
- Ensuring necessary and helpful content elements are included.
- They improve users searchability within a website.
- Aiding the process of matching search intent to the best answer.
- Including SEO structured data within the website’s HTML code.
- Increasing your website’s visibility in search engine result pages (SERPs).
- Increasing your chances of gaining rich snippets.
- Simplifying how search engines view the relationships between content pieces on your website.
- Driving qualified clicks to you website from interested users.
- Improving the accuracy of query matching results.
- They help get your data included in your Google Knowledge Graph.
The Schema.org vocabulary is ideal for making semantic triple statements that combine to generate graphs of interconnected resources. When building knowledge graphs, nodes in these triples store information in what we call “triplestores”. The SPARQL query language for RDF can be crafted to target specified triples. In this way, your website article optimization can be better integrated and connected to your World Wide Web of Data.
They can become more complicated and more expressive by using more complex models. We often create triples as objects or subjects of other triples. This provides semantic search benefits for websites we manage.
I enjoy the study of which specifics help achieve the right schema architecture for a given website. Semantic expressivity can take many form. Consider the following.
(, worked at, ) (, studied at, ) (, is author of, ) (, is headquartered in, ) (, partnered with, ) (, was created by, ) (, edited by, ) (, was funded by, ) (, was founded by, ) (, worked with, ) (, was created for, ) (, reviewed by, )
Knowledge Graph Semantic Embedding (KGSE)
This learning framework combined with triple semantic information is at the core of the core of many artificial intelligence applications, such as intelligent search, and AI question answering information retrieval.
“KGSE comprehensively considers the structural embedding and semantic embedding of triples, where semantic embedding is used as a supplement to improve the quality of embedding. Specifically, KGSE uses the improved TransD model to obtain the structural embedding of triples, and employs the deep convolutional neural model combined with an attention mechanism to obtain the semantic embedding of triples.” – A Knowledge Graph Embedding Framework With Triple Semantics [3]
How do schemas assist semantic search?
Google crawler parses your web data and converts it into triples that it can insert in a graph database. Triples are the universal and fundamental atom of web information. In our practice, this is why knowledge of how the semantic triple works is foundational to optimizing structured data and content for semantic search and KGSE.
Metadata formats represent knowledge in a machine-readable way. Every part of schema.org triple is individually addressable via a unique ID. URI can be used to represent those IDs — for example, the statement “Benson married Jane” may be enriched by schema as:
{“@context”: “https://schema.org”,
“@type”: “Person”,
“@id”: “Person1”,
“name”: “Benson”,
“knows”: {
“@context”: “https://schema.org”,
“@type”: “Person”,
“@id”: “Person2”,
“name”: “Jane”
}}
All information fragments are understood, stored, and accessed as triples in schema.org.
Triples are important in semantic search. When we consider how Google’s Knowledge Graph is rapidly expaning in the era of AI, business context and semantics play a vital part in SEO strategies. On-page semantic triples offer micro details that Google’s Merchant Center feed uses for product validation purposes.
The searcher’s intent and context behind a search query have removed former reliance on exact match keywords.
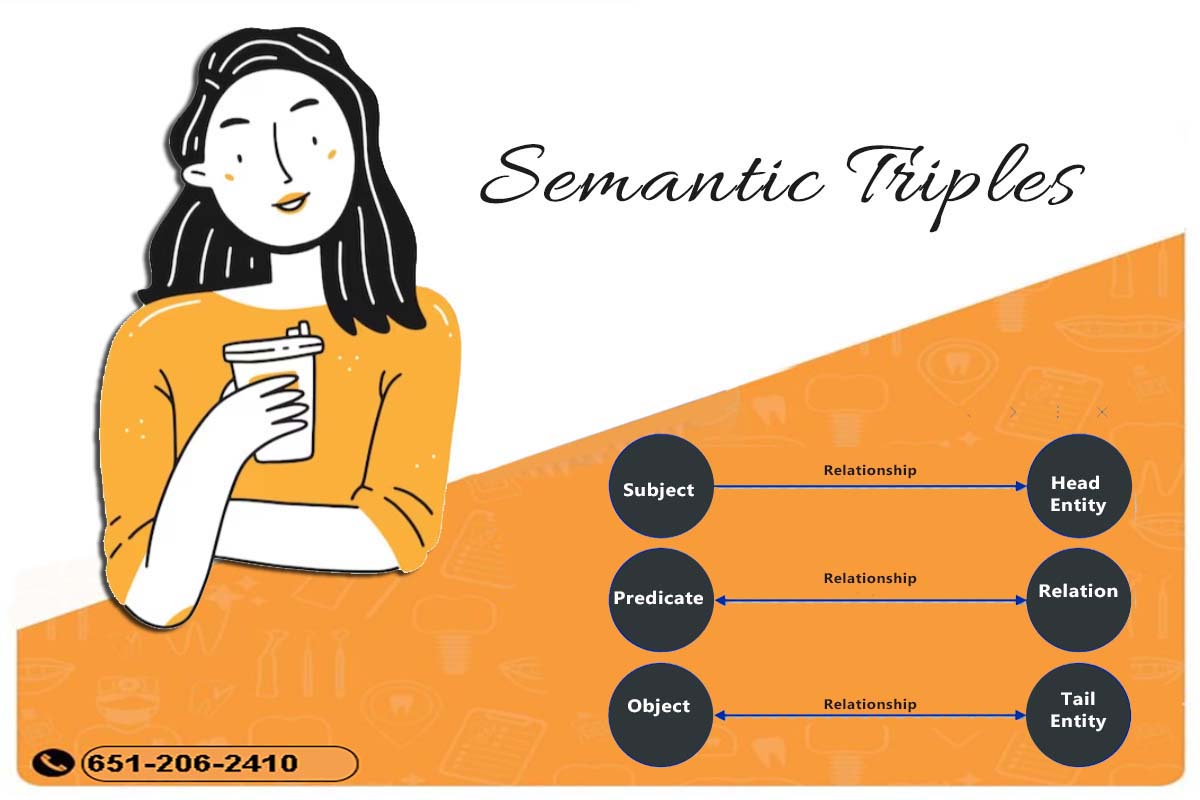
What are the components of a semantic triple?
Head Entity → Relation → Tail Entity
Subject → Predicate → Object
The subject references the entity being described, the predicate is used to explain the relationship between the subject and object, and the object refers to the entity being related to the subject.
Semantic triples are commonly used in natural language processing and machine learning to help search engines and computers understand and interpret the meaning of your text. They understand content easily by finding connections and patterns on web documents.
Knowing how each element of a semantic triple works means that you can optimize it. More importantly, applying this knowledge to a semantic network can inform Google of three different relevant entities. Each ID is an entity, and each entity owns properties. Each element is unique and yet interrelated; you can explain their value and context.
Here are some examples of basic semantic triples:
- “Konrad drives buses”
- “Samantha is caucasian”
- “Timothy plays Agricola”
Semantic triple code is formated so that it’s machine-readable. Each component of a triple can be identified using unique URIs. This is what makes them useful in resource description frameworks. The third statement above might be encoded as:
https://example.name#Timothy https://xmlns.com/foaf/0.1/plays https://example.name#Agricola
How triples express graph data
Knowledge graph completion (KGC) seeks to predict missing links based on known triples.
Semantic triples are commonly stored in a graph-like format, with single triple components representing a unique relationship between three elements. This is in contrast to array and list data structures which are often stored in a linear or hierarchical sequence.
Leveraging entity relationships and structured information found in triples can boost your content marketing’s performance. You can assist the discovey of related entities on a specified web page by identifying the parent and children (tail entity) of its named entities. This adds structure to your content; it helps search engines when evaluating you as the expert that searchers seek.
Every web page can have a clear data graph when published using linked data. Better data management, strong typing, and a common, clear data model can deliver your site’s content in a more useful way.
I like to think of triples as word neighborhoods. Every house may be different on your street with different people living in them; but they share the same neighborhood. When SEOs and schema markup experts seek to explain entities and relations within a content piece, this concept is helpful. Semantic relevance and triplet classification come into play.
Knowledge graph embedding adversarial learning (HARPA) creates a way “to learn the information oftriples and neighborhoods at the triples-level and further utilizes the rich inference information of paths to deeply learn relation embedding at the paths-level.” [4]
Testing your semantic triples
While I utilize Google tools for validating schema types, testing, and implementation; the need is to go beyond that and rely on practical knowledge. Jarno van Driel shared the following nugget of wisdom with me.Jarno van Driel shared the following nugget of wisdom with me.
Google’s position is that if you are able to provide advanced markup than you should also be able to judge whether the warnings/errors are correct or not. Their tooling only reports about the things they officially support, limited to the examples they provide themselves. Anything beyond their examples is something their tooling really isn’t meant for. – Jarno Van Driel
Semantic Triples are Machine-Readable Representations of Knowledge
Schemas are helpful in organizing and marking up web page content for easier search engine consumption. Schemas assist is establishing connections between entities, such as products, people, services, organizations, events, and more. By using schema markup on your website to express semantic triples, it helps search engines establish relevance between your content, your brand entities, and the knowledge graph in relation to user queries.
They also help user searchability of a website, especially for larger sites.
They provide suplemental context so that people can gain more relevant and useful search results.
Complex triple:To put this into a practal business application, consider the use of Organization schema. We’ll start with a simple semantic triple example.
Amazon sells products.
Organization structured data can accomplish a lot of hard work. It can define the brand entity name, logo, contact details, hours, Google map URL, and social profiles of the organization.
A complex triple maybe “My sister, and I are shopping on Amazon for new winter coats and color-coordinated boots.” Here, a lot more data information is provided versus “Amazon sells products”.
Preparedness for Google’s Search Generative Experience and Gemini is imperative. Schemas that take into account the Knowledge Graph facilitate better user experiences and offer more context for search engines. You can future-proof your digital presence by implementing structured data and adhering to the appropriate content hierarchy, architecture, and semantic triples.
SUMMARY: Semantic Triples Boost Context and Meaning of Content
When you utilize schema markup and semantic triples, you are providing chances for improved search accuracy for knowledge graph embedings. Embrace semantic web principles by effectively leverging tools like RDF, named graphs, and node relational datasets. Regularly audit and optimize your schema markup to ensure it remains up-to-date and avoid schema markup drift. Google continues to rely on good markup best pratices to deliver search results.
Call 651-206-2410 for your Schema Markup Audit
Resources
[1] https://en.wikipedia.org/wiki/Named-entity_recognition
[2] https://www.w3.org/TR/rdf12-n-triples/
[3] https://ieeexplore.ieee.org/document/10077479
[4] https://link.springer.com/article/10.1007/s10618-022-00888-3